混合精度训练简介
传统的模型训练一般使用FP32精度进行训练。近年来,由于模型越来越大,我们希望在有限的显存中训练更大的模型,也希望能够提高训练速度,因此,人们开始研究如何在混合使用低精度的参数进行模型训练时,保持模型的性能。
浮点数据类型介绍
要理解混合精度训练,最好先把“浮点数”这件事想清楚。计算机里存一个浮点数,并不是直接把十进制小数塞进去,而是把它拆成三块:符号位决定正负,指数位决定这个数大概落在哪个数量级,尾数位决定这个数量级里还能分得多细。粗略写出来就是:
所以同样是一个 16 bit 或 32 bit 的数字,指数位多一点,能表示的范围就更大;尾数位多一点,相邻两个可表示数字之间就更密,数值就更精细。混合精度训练里的很多选择,本质上都是在这两个方向之间做取舍:我们到底更怕数值溢出,还是更怕舍入误差。
FP32 是最传统的训练精度,它用 1 bit 存符号、8 bit 存指数、23 bit 存尾数,一共 4 bytes。它的好处是范围够大、精度也够细,所以不管是前向计算、反向梯度,还是优化器里长期累积的小更新,都比较稳。问题也很直接:每个参数 4 bytes,模型一大,权重、梯度、优化器状态很快就把显存吃完;同时 GPU 做矩阵乘时,低精度 Tensor Core 往往能给出更高吞吐,继续全程 FP32 就显得有点浪费。
FP16 看起来像是最自然的压缩版本:它只有 2 bytes,显存直接减半,而且 10 bit 尾数比 BF16 更细。但 FP16 把指数位压到了 5 bit,动态范围小很多;按照 IEEE FP16 的编码规则,它的最大有限值是 65504。训练里一旦激活值、loss scale 或梯度中间值稍微大一点,就容易上溢成 inf;梯度太小的时候又容易下溢成 0。因此早期 FP16 训练通常要配合 loss scaling,把 loss 先放大再反传,尽量让梯度落在 FP16 能表示的区间里。
BF16 的设计思路刚好不一样。它同样是 2 bytes,但保留了和 FP32 一样的 8 bit 指数,只把尾数缩到了 7 bit。也就是说,BF16 的动态范围几乎和 FP32 一样,训练中不太容易因为量级问题直接爆掉;代价是同一个数量级里的刻度更粗,精度比 FP16 还低。这个取舍非常适合深度学习里的矩阵乘:神经网络本身对一点舍入噪声比较耐受,而大范围可以显著减少上溢、下溢问题。所以现在做大模型训练或微调时,BF16 往往比 FP16 更省心。
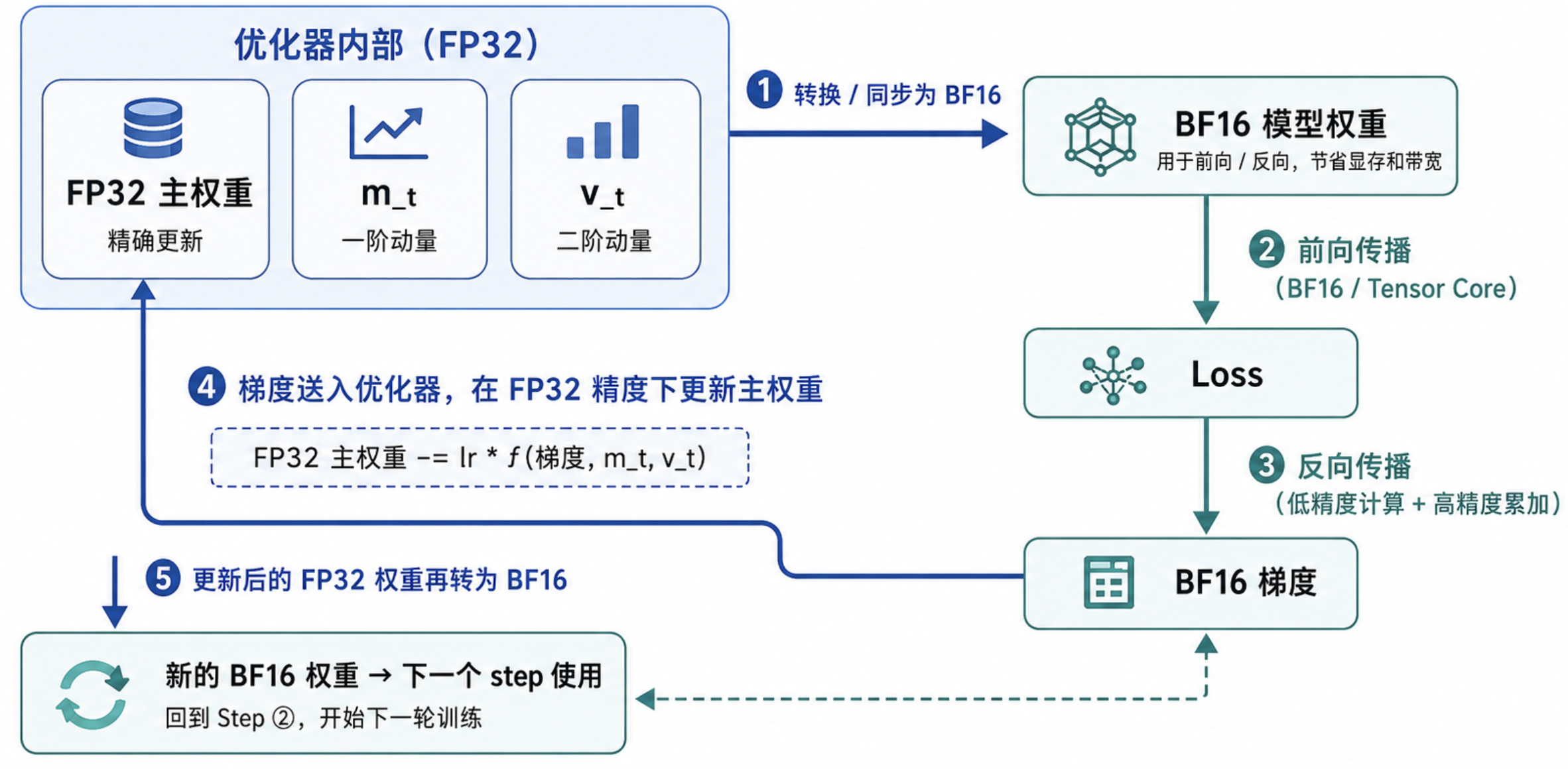
这也解释了为什么后文会把 BF16 放在前向和反向传播里,却仍然让优化器保存 FP32 主权重。前向/反向主要是大批量矩阵乘和激活函数,低精度误差通常会被模型和 batch 噪声“吃掉”;优化器更新则是在做长期累加,很多时候是把一个很小的 lr * grad 加到一个已经存在的权重上。如果权重只保存在 BF16 里,这个微小更新可能连最小刻度都碰不到,直接被舍入掉。于是计算可以低精度,状态累积仍然要高精度,这就是混合精度训练里最核心的分工。
再往下压就是 FP8。PyTorch 里常见的两个 FP8 类型是 torch.float8_e4m3fn 和 torch.float8_e5m2。前者可以理解成 4 bit 指数、3 bit 尾数,精度稍好但范围更小;后者是 5 bit 指数、2 bit 尾数,范围更大但刻度更粗。实际训练里,FP8 通常不会像 BF16 那样直接替换所有计算,而是要配合 scaling,把张量按块或按通道缩放到合适区间,再交给硬件做低精度矩阵乘。直觉上可以把它看成比 BF16 更激进的带宽和算力优化:收益更大,但对数值缩放、算子支持和训练框架的要求也更高。
混合精度训练的完整工作流
下面以 AdamW + BF16 计算为例。先说明一下,这里讨论的是大模型训练里很常见的一种实现方式:前向、反向使用 BF16 权重和激活来降低显存与带宽压力,优化器内部仍然维护 FP32 主权重和 FP32 动量状态。不同框架的细节会有差异,比如 PyTorch AMP 可能让参数本体保持 FP32,只在算子执行时临时 autocast,但背后的数值逻辑是一样的:计算可以低精度,长期累积的训练状态最好保留高精度。
如果只看模型状态,不考虑激活值,一个参数在 AdamW + BF16 混合精度全量微调中大致会占:
所以一个常用的粗估是:
实际估算时我一般会把模型状态按 16 到 18 bytes/param 留余量,因为不同实现里还会有参数对齐、通信 bucket、梯度临时副本、fused optimizer workspace 等额外开销。真正容易被低估的往往是激活值,它和 sequence length、micro batch size、是否开启 activation checkpointing 强相关;有时候模型状态算得很准,最后还是爆在激活值上。
为什么优化器必须保存 FP32 主权重?
最核心的原因是权重更新通常非常小,而 BF16 在某个数值附近能分辨的刻度又比较粗。BF16 只有 7 bit 显式尾数,算上隐含的最高位,大约可以理解成 8 bit 有效精度;在 1.0 附近,相邻两个 BF16 数之间的间隔约为 ,也就是 0.0078125。FP32 的尾数细得多,在 1.0 附近的间隔约为 ,也就是 1.19e-7。
训练里一次参数更新大概长这样:
如果学习率是 1e-5,梯度量级又差不多是 1,那么这一步更新就是 1e-5。对于 FP32 来说,这个变化明显大于 1.0 附近的最小刻度,所以权重会真实发生变化;虽然十进制的 1.00001 本身不一定能被二进制浮点数精确表示,但这个更新不会被整个抹掉。对于 BF16 来说就不同了,1e-5 远小于 0.0078125,1.0 + 0.00001 四舍五入之后仍然很可能回到 1.0。
这就是所谓的 swamping problem:大数加小数时,小数被低精度格式的刻度吞掉。它麻烦的地方不在于某一步误差稍微大一点,而在于训练本来就是几千步、几万步的小更新累积。如果每一步都在 BF16 权重上直接更新,大量微小变化会反复消失,模型看起来在反传,实际上参数没有按预期移动。
AdamW 里的 m_t 和 v_t 也有类似问题。它们是梯度的一阶、二阶指数滑动平均,本质上也是长期状态。如果这些状态本身就用低精度保存,早期的细小变化和后期的微调信号都会更容易被量化误差污染。所以常见做法是:计算权重可以是 BF16,优化器读到梯度后,仍然在 FP32 主权重、FP32 m_t 和 FP32 v_t 上完成更新,再把新的权重同步回低精度计算副本。
为什么前向/反向传播可以用 BF16?
看起来这好像有点矛盾:既然优化器更新这么怕 BF16,为什么前向和反向又能用 BF16?关键在于,这两类计算对误差的敏感方式不一样。
前向传播主要是一层层矩阵乘、归一化、激活函数和残差连接:
BF16 和 FP32 一样有 8 bit exponent,动态范围接近 FP32,因此相比 FP16 更不容易因为量级问题上溢或下溢。这里不能说“不会溢出”,极端输入、异常 loss、错误的初始化照样会把数值打爆;更准确的说法是,BF16 把 FP16 最头疼的动态范围问题缓和了很多。尾数少带来的舍入误差依然存在,但神经网络训练本身就带有 mini-batch 采样噪声、dropout、数据增强等随机性,很多局部舍入误差不会像优化器状态那样长期原封不动地累积。
反向传播也类似。梯度当然不是越粗越好,但它本身就是从一个 mini-batch 估计出来的随机量,我们通常更关心整体方向和统计趋势,而不是每个元素最后几位小数完全准确。更重要的是,现代 GPU 上很多低精度矩阵乘并不是“从头到尾都 BF16”:常见路径是 BF16 输入,内部用更高精度做累加,再输出 BF16 或 FP32 结果。框架也经常会让 softmax、LayerNorm、loss 计算这类敏感算子保留更高精度。
所以这里不能简单概括成“乘法可以低精度,累加必须高精度”。矩阵乘本身就包含大量累加,只是这些累加通常发生在受控的算子内部,并且硬件和框架会用更稳的 accumulate 精度处理。优化器更新的问题更特殊:它是在同一个持久化权重上反复加一个很小的增量,w = w + lr * grad 这种“大数吃小数”的场景正好是低尾数精度最容易翻车的地方。
因此混合精度训练的直觉可以总结成一句话:把吞吐量最大的前向/反向计算交给 BF16,把最怕长期量化误差的优化器状态留在 FP32。这样既吃到低精度硬件的速度和显存收益,又尽量不破坏训练过程中真正需要细粒度累积的部分。