FSDP-Zero123分片简介
随着模型越来越大,单卡显存已经无法满足训练需求,人们使用多种手段来扩大训练规模,如使用混合精度减少参数内存占用,或是使用多卡通信的方法进行并行训练。ZeRO 是常见的数据并行模型状态分片方案,思路为将模型权重、梯度、优化器状态等训练状态分片到多张卡上。
这里需要先区分 ZeRO 分片和 tensor parallel。ZeRO-3 也会分片模型权重,但它分片的是模型状态的常驻存储:每张卡平时只保存一部分权重,真正计算某一层时再临时 AllGather 出这一层需要的完整参数。tensor parallel 则是把一层里的矩阵乘、attention head、MLP hidden dim 等计算本身切开,多张卡共同完成同一个 batch 的同一层计算。ZeRO 的核心问题是“状态放不下,怎么存”,tensor parallel 的核心问题是“单层算不动,怎么切计算”。
参数组成
假设使用AdamW + BF16 进行混合精度训练,则在训练过程中,需要存储的参数组成如下:
| 组件 | 精度 | 每参数字节数 | 用途 |
|---|---|---|---|
| 模型权重(计算用) | BF16 | 2B | 前向/反向计算 |
| 梯度 | BF16 | 2B | 反向传播产出,供优化器更新参数 |
| FP32 主权重(优化器) | FP32 | 4B | 保存更高精度的参数副本,用于稳定更新 |
| 一阶动量 m_t | FP32 | 4B | AdamW 对梯度均值的指数滑动平均 |
| 二阶动量 v_t | FP32 | 4B | AdamW 对梯度平方的指数滑动平均 |
BF16 模型权重主要服务于矩阵乘等实际计算,可以显著降低显存和带宽压力;梯度是反向传播阶段产生的临时训练信号,优化器会读取它来决定参数更新方向;FP32 主权重、m_t、v_t 则属于 AdamW 的优化器状态,通常用更高精度保存,以减少长时间训练中的数值误差。
可见训练情况下,参数占用的大头在优化器状态上
不分片时:每张卡都持有完整的一份,即 N × (2+2+4+4+4) = 16N 字节(不算激活值)。
训练流程梳理
先不考虑 ZeRO 分片,只看普通多卡 DDP 的训练流程。DDP 中每张 GPU 都持有一份完整的模型权重和优化器状态,但每张卡读取的数据不同。例如 8 卡训练时,一个 global batch 会被切成 8 份 micro-batch,每张卡只负责其中一份。前向传播时,每张卡用自己本地的完整 BF16 模型权重计算输出,并保存反向传播需要的激活值。
反向传播时,每张卡根据自己的 micro-batch 计算本地梯度。此时不同 GPU 上的梯度并不相同,因为它们看到的数据不同。如果直接用各自的梯度更新参数,8 张卡的模型副本会从这一步开始分叉,后续训练就不再等价于单个大 batch 的训练。因此 DDP 会在反向传播过程中对梯度做 AllReduce,把所有卡的梯度求和或平均,并把同步后的梯度写回每张卡本地。
梯度同步完成后,每张卡都拥有相同的模型权重、相同的平均梯度,以及相同的 AdamW 优化器状态。随后每张卡各自在本地执行 optimizer step,读取 BF16 梯度、FP32 主权重、m_t 和 v_t,计算出完全相同的参数更新。因为更新前的状态相同、梯度也已经同步,所以更新后的模型副本仍然保持一致。
这个流程的好处是实现简单、计算并行度高,每张卡都可以独立完成完整模型的前向和反向。代价是显存冗余很大:模型权重、梯度和优化器状态在每张卡上都完整复制了一份。ZeRO 后续要优化的正是这部分冗余存储。
ZeRO Stage 1:分片优化器状态
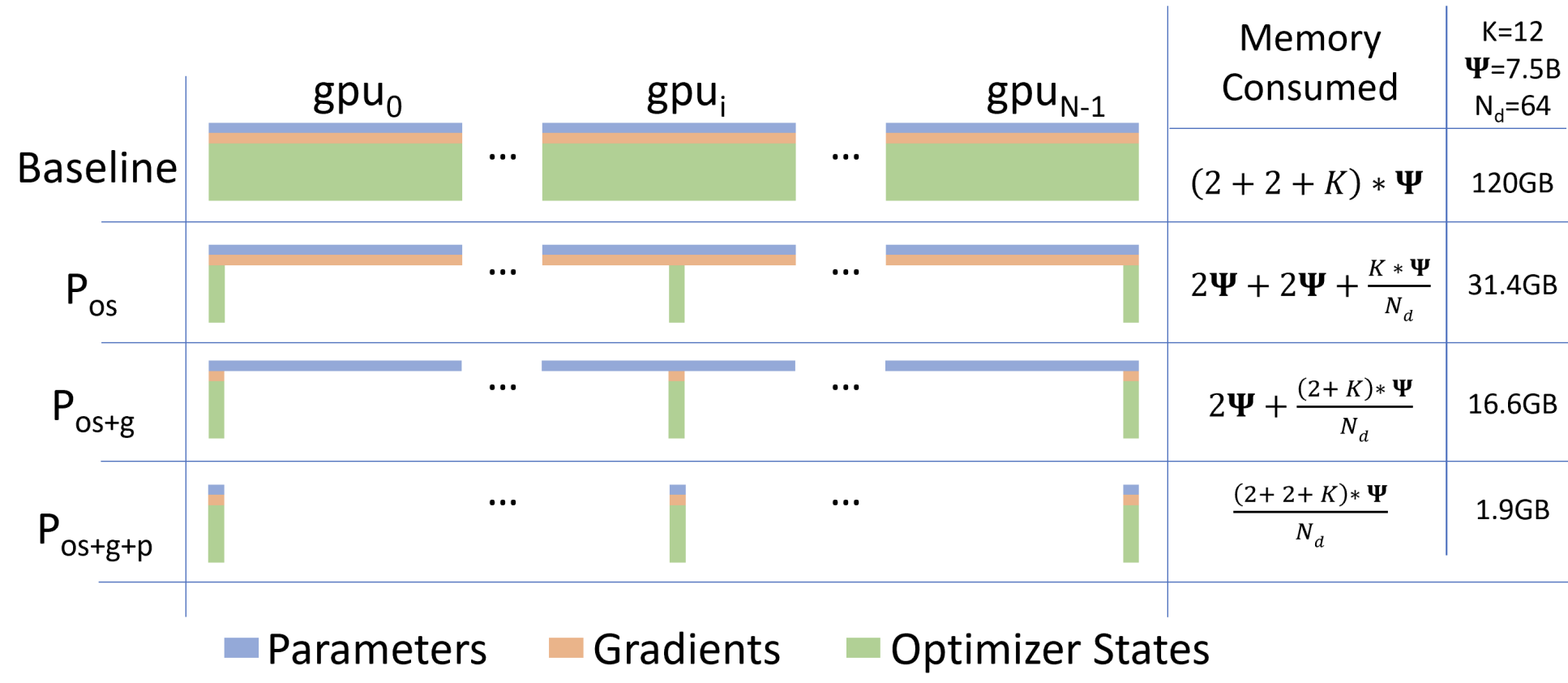
ZeRO-1 先处理最大的一块冗余:优化器状态。在普通 DDP 里,每张卡不仅保存完整的 BF16 计算权重和 BF16 梯度,还保存完整的 FP32 主权重、m_t、v_t。如果使用 AdamW,这三项合起来是 12N 字节,比 BF16 模型权重本身大很多。ZeRO-1 的做法是:BF16 模型权重和 BF16 梯度仍然完整复制在每张卡上,但把 FP32 主权重、m_t、v_t 按参数范围切成 8 份,每张卡只负责其中 1 份。
┌──────────────────────────────────────────────────┐
│ 8 张 GPU 各自持有 │
│ │
│ 完整 BF16 模型权重 N × 2B │
│ 完整 BF16 梯度 N × 2B │
│ │
│ 分片优化器状态 │
│ • 1/8 的 FP32 主权重 N/8 × 4B │
│ • 1/8 的 m_t N/8 × 4B │
│ • 1/8 的 v_t N/8 × 4B │
└──────────────────────────────────────────────────┘
训练时,ZeRO-1 的前向和反向基本仍然像 DDP 一样执行。每张卡都有完整 BF16 权重,所以可以独立完成自己 micro-batch 的 forward/backward;反向传播得到的梯度也会像普通 DDP 一样做 AllReduce,使每张卡都拿到完整的平均梯度。
区别发生在 optimizer step。由于 GPU0 只保存第 0 片参数的 FP32 主权重和 AdamW 动量,GPU1 只保存第 1 片,以此类推,所以每张卡只更新自己负责的那 1/8 参数。更新完成后,各卡会把自己更新好的参数分片同步给其他卡,所有卡再把这些分片拼回本地完整的 BF16 模型权重。这样下一轮 forward 时,每张卡仍然能看到完整且一致的模型。
从通信角度看,ZeRO-1 仍然保留 DDP 的梯度 AllReduce;额外需要在参数更新后同步各自更新的参数分片。它的优点是对计算流程改动较小,因为 forward/backward 期间每张卡仍有完整模型;缺点是梯度和 BF16 权重还没有省,显存优化只作用在优化器状态上。
每卡显存:2N + 2N + (4N+4N+4N)/8 = 5.5N 字节(vs 原来 16N)
节省的是:FP32 主权重、m_t、v_t 这 12N 优化器状态从完整保存变成按卡分片。
ZeRO Stage 2:分片优化器状态 + 梯度
ZeRO-2 在 ZeRO-1 的基础上继续观察一个事实:既然每张卡只负责更新 1/8 的参数,那么它其实也只需要这 1/8 参数对应的平均梯度。Stage 1 中每张卡保留完整梯度,是为了和普通 DDP 的流程保持一致;Stage 2 则把这部分也分片掉。
┌──────────────────────────────────────────────────┐
│ 8 张 GPU 各自持有 │
│ │
│ 完整 BF16 模型权重 N × 2B │
│ │
│ 分片梯度 │
│ • 1/8 的 BF16 梯度 N/8 × 2B │
│ │
│ 分片优化器状态 │
│ • 1/8 的 FP32 主权重 N/8 × 4B │
│ • 1/8 的 m_t N/8 × 4B │
│ • 1/8 的 v_t N/8 × 4B │
└──────────────────────────────────────────────────┘
普通 DDP 的梯度同步可以理解为“先把所有卡的梯度求和,再把完整结果发回每张卡”。ZeRO-2 把这个过程改成 Reduce-Scatter:仍然对所有卡的梯度求和或平均,但最终结果不是完整复制给每张卡,而是按参数范围 scatter 出去。GPU0 只拿到第 0 片平均梯度,GPU1 只拿到第 1 片平均梯度,刚好和各自保存的优化器状态对应。
这样做在数学上仍然等价于 DDP 的全局平均梯度更新,只是每张卡不再保存自己不负责的梯度部分。随后 optimizer step 和 ZeRO-1 类似:每张卡读取自己的梯度分片、FP32 主权重分片、m_t 分片和 v_t 分片,更新自己负责的参数。因为 BF16 模型权重在 Stage 2 里仍然完整复制在每张卡上,所以更新后的参数分片仍需要同步给所有卡,让每张卡本地的完整 BF16 权重保持一致。
实际实现通常会按 bucket 或按 layer 边反向、边 Reduce-Scatter、边释放梯度缓存,而不是等整个模型的梯度都算完再统一处理。因此下面的公式更接近稳定状态下的模型状态占用;真实峰值还会受到 bucket 大小、梯度累积、通信重叠策略影响。
每卡显存:2N + (2N+4N+4N+4N)/8 = 3.75N 字节
节省的是:在 Stage 1 基础上,梯度也从 2N → 0.25N。
ZeRO Stage 3:分片一切(优化器状态 + 梯度 + 模型权重)
ZeRO-3 再进一步,把计算用的 BF16 模型权重也分片保存。到这一步,每张卡常驻的模型状态只剩自己负责的 1/8:BF16 参数分片、BF16 梯度分片、FP32 主权重分片、m_t 分片和 v_t 分片。它和 tensor parallel 的关键区别是:ZeRO-3 并不是把某个矩阵乘的计算永久切给不同 GPU,而是把参数平时分片存放;真正执行某个 module 的计算前,再临时收集出这个 module 需要的完整参数。
┌──────────────────────────────────────────────────┐
│ 8 张 GPU 各自持有 │
│ │
│ 分片 BF16 模型权重 N/8 × 2B │
│ 分片 BF16 梯度 N/8 × 2B │
│ 分片 FP32 主权重 N/8 × 4B │
│ 分片 m_t N/8 × 4B │
│ 分片 v_t N/8 × 4B │
└──────────────────────────────────────────────────┘
前向传播时,框架会在进入某一层或某个 FSDP unit 前,对这一段参数做 AllGather。AllGather 之后,每张卡临时拥有这一层的完整 BF16 权重,于是可以像普通数据并行一样,用自己的 micro-batch 完成这一层计算。计算结束后,非本卡负责的参数分片可以释放,只保留本卡原本负责的 shard。
反向传播时也类似。计算某一层的 backward 需要对应的权重,因此可能再次 AllGather 这一层参数;得到梯度后,再用 Reduce-Scatter 把梯度规约并切回各个 rank。最终每张卡只保留自己负责的梯度分片,并用它更新本地的 FP32 主权重、m_t、v_t 和 BF16 参数分片。
和 ZeRO-1/2 不同,ZeRO-3 更新完参数后不需要把完整模型权重常驻同步到每张卡,因为每张卡本来就不保存完整权重。下一次 forward 需要某一层参数时,再从各卡当前持有的参数分片 AllGather 出来即可。这个设计把常驻显存压到最低,但把参数通信放进了 forward/backward 的关键路径。
每卡显存:(2N+2N+4N+4N+4N)/8 = 2N 字节
这个 2N 指的是理想情况下每卡常驻的模型状态。真实训练峰值会更高,因为某些时刻会临时持有当前层 AllGather 出来的完整参数、通信 bucket、prefetch 参数以及激活值。ZeRO-3 的核心取舍就是:用更多、更频繁的参数 AllGather,换取模型状态显存近似按数据并行卡数线性下降。
通信代价的直觉
- ZeRO-1:梯度同步仍然接近普通 DDP,额外多了参数更新后的同步,整体通信压力通常可控。
- ZeRO-2:用 Reduce-Scatter 替代 AllReduce 梯度同步,通信总量和 DDP 同阶,但每张卡只保留梯度分片。
- ZeRO-3:前向和反向会按层 AllGather 参数,反向后再 Reduce-Scatter 梯度。它的显存收益最大,但速度更依赖网络带宽、分片粒度、通信计算重叠和框架实现。
Zero分片与张量并行组合使用
假设有 8 张 GPU,设置 tp_size=2、dp_size=4,那么可以把相邻两张卡组成一个 TP group,共同切分同一个模型副本中的张量计算:
TP groups:
[GPU0, GPU1], [GPU2, GPU3], [GPU4, GPU5], [GPU6, GPU7]
这 4 个 TP group 之间再构成数据并行关系,每个 group 处理不同的 mini-batch。为了让同一个 tensor-parallel 分片位置之间同步梯度或分片优化器状态,通常会按 TP rank 位置组成 DP group:
DP groups:
[GPU0, GPU2, GPU4, GPU6] # 每个模型副本里的第 0 个 TP 分片
[GPU1, GPU3, GPU5, GPU7] # 每个模型副本里的第 1 个 TP 分片
这样,一层内部的计算由 TP group 内的两张卡协作完成;不同数据 batch 之间的梯度同步、优化器状态分片,则发生在 DP group 内。ZeRO/FSDP 通常作用在 DP group 维度上,而不是替代 tensor parallel 的算子切分。
FSDP 和 ZeRO 的关系
PyTorch FSDP 可以理解为 ZeRO 思路在 PyTorch 里的实现之一。常见对应关系是:
| FSDP 策略 | 近似对应 | 说明 |
|---|---|---|
NO_SHARD | DDP | 不分片参数、梯度和优化器状态 |
SHARD_GRAD_OP | ZeRO-2 | 分片梯度和优化器状态,参数在计算时保持完整 |
FULL_SHARD | ZeRO-3 | 分片参数、梯度和优化器状态 |
HYBRID_SHARD | ZeRO-3 + 层级分组 | 组内分片,组间复制,常用于多机多卡 |
实际训练时还需要额外考虑激活值、通信 bucket、临时 AllGather 出来的完整参数、CUDA allocator 碎片以及 checkpoint 保存方式,所以这些公式更适合用来建立显存组成的直觉,而不是直接等同于最终峰值显存。